
이번 포스팅에서는 이전 포스팅에서 개괄적으로 분류해보았던 Supervised Learning과 Unsupervised Learning에 대해서 좀 더 구체적으로 정리를 해보고자 한다.
Supervised Learning ?
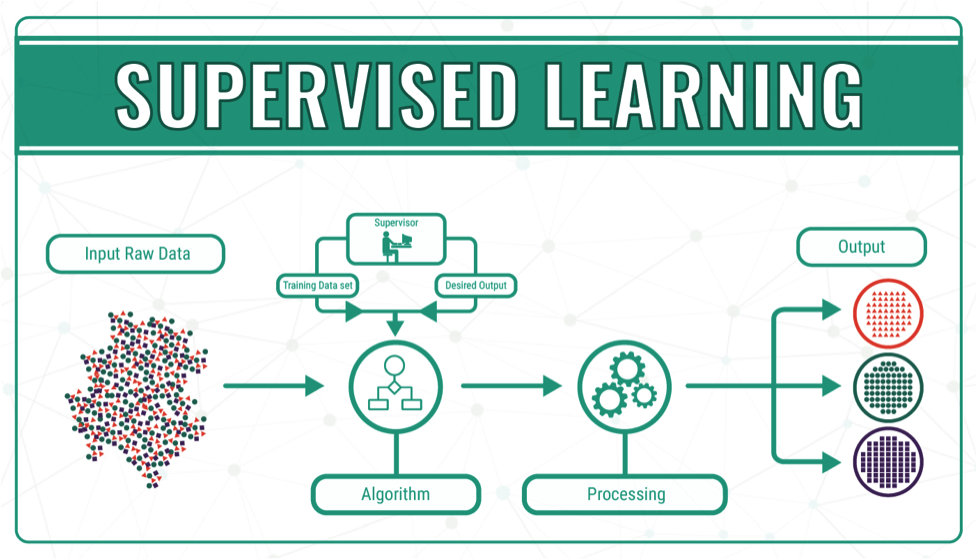
이전 포스팅에서 알아보았듯이 Supervised Learning이란 (X(input), Y(output))에서 Y(output)에 대한 값이 labeling을 통해 주어지고, 이를 통해 X(input)값이 유추되는 형태이다.
Y의 값이 direct feedback으로 주어지고, Y 데이터의 형태에 따라 두 가지 형태로 분류된다.
Y labels are continuous =
Regression
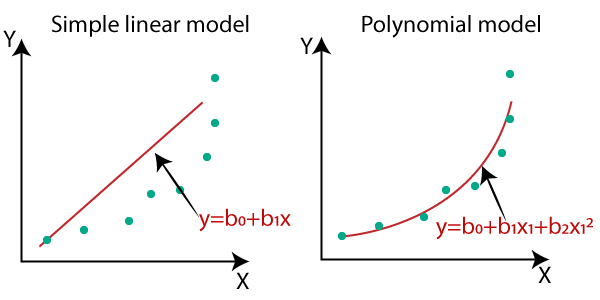
Regression은 크게 Linear Regression과 Polynomial regression으로 분류된다.Polynomial regression은 레이블이 다항식 관계에 있는 경우이며, 2차 3차 함수의 계수 형태로 존재한다.
- Y labels are discrete =
Classification
Y 데이터가 아래와 같이 discrete형태로 분류된다면 이는 supervised learning의 classification로 분류된다.
ex)
(1) SVM (Support Vector Machine) : 기계학습의 분야 중 하나로 패턴 인식, 자료 분석을 위한 지도학습 모델이며, 주로 분류와 회귀 분석을 위해 사용된다.
(2) 신경망(Neural Network) : 신경망은 인간의 뇌 행동을 반영한다. 인간의 뇌 행동에 있어, 컴퓨터 프로그램은 특정 패턴을 인지하고 AI, 머신러닝, 딥러닝 분야에서의 일반적인 문제들을 해결하는 것 또한 허용한다.
신경망은 Artificial Neural Networks(ANNs) 또는 Simulated Neural Networks(SNNs)로 알려져있다.
이 신경망 개념은 머신러닝의 부분집합 개념이자, 딥러닝 알고리즘의 핵심적인 부분이다.
이 신경망이라는 이름과 구조는 인간의 뇌로부터 영감을 받았으며, 생물학적인 뉴런들의 시그널을 주고받는 방식을 모방하였다.
- 퍼셉트론(Perceptron)
인공 신경망은 수많은 머신 러닝 방법 중 하나로, 딥 러닝을 이해하기 위해서는 우선 인공 신경망에 대한 이해가 필요하기 때문에 초기 인공 신경망인 퍼셉트론(Perceptron)에 대한 이해가 필요하다.
[참고] https://wikidocs.net/24958
- 다층 퍼셉트론(MultiLayer Perceptron, MLP)
(3) 의사결정 나무(Decision tree) : 의사결정나무는 DTs라고도 하며 여러가지 규칙을 순차적으로 적용하며서 독립 변수 공간을 분할하는 분류 모형이다. 분류(Classification)와 회귀 분석(Regression)에 모두 사용될 수 있기 때문에 CART(Classification And Regression Tree)라고도 한다.
(4) 나이브 베이즈 분류(Naive Bayes classification) : 스팸메일 필터, 텍스트 분류, 감정 분석, ㅊ투천 시스템 등에서 광범위하게 활용되는 분류기법이다. 나이브 베이즈 모델인 용어에서 알 수 있듯이, Naive(단순한, 순진한, 전문성이 없는)한 모델임을 알 수 있다. 나이브 베이즈 모델은 모든 feature(속성)가 동등하게중요하고 독립적이라고 가정한다. 하지만 실생활에서 각 feature(속성)들 간에 독립성을 보장하기는 쉽지 않기 때문에 실생활에 바로 적용하기에는 어려움이 있다.
참고 - 머신러닝 관련 블로그 글 (bkshin tistory)
(5) K-nearest neighbors(K-NN) : 지도 학습 기반에 한 종류로 거리기반 분류분석 모델이라고 할 수 있다. 기존 관측지의 Y값(Class)가 존재한다는 점에서 비지도학습인 클러스터링(Clustering)과 차이가 있다.
유유상종이라는 말이 있다. 같은 날개를 가진 새들끼리 함께 모인다는 말인데, K-NN 알고리즘을 설명하기 적합한 속담이다. 머신러닝에서 데이터를 가장 가까운 유사 속성에 따라 분류하여 데이터를 분류하는 기법이 바로 K-NN 알고리즘 기법이기 때문이다.
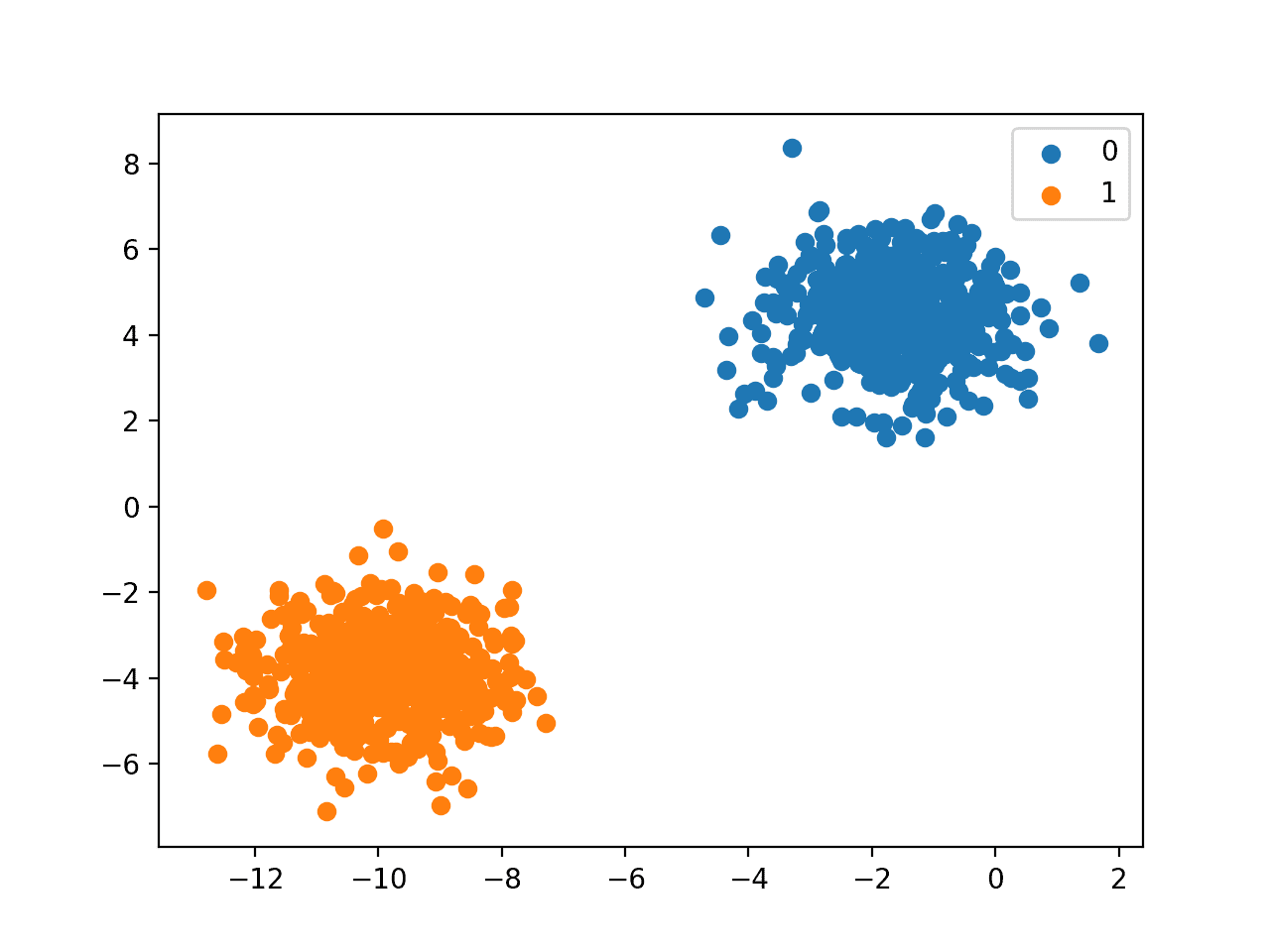
Classification model 예시
분류 모델의 예시로는 대표적으로 문서 분류 Sports, Politics, science … topic 별로 분류하는 것과 e-mail 중 ham vs spam SNS 내용중에 sentiment: negative, confidence: 99%, trend: boring 과 같은 감성적인 내용으로의 분류의 예시가 있다.
이외에도 아래의 분류 관련 예시들이 있다.(1) Image Classification : ImageNet Competetion(2) Video Classification : 영상의 frame을 쪼개서 분석(3) Object Detection(4) Video Summarization : 범죄 현장에서 수사에 활용되는 기법으로 다른 시간대의 물체가 동시간대에 시간만 다르게 labeling 되어 표시된다.(5) Image Captioning : 이미지에 대한 설명 label X와 Y의 관계를 규명 (Image caption)(6) Speech Recognition : X(Speech data), Y(대응 텍스트 - 영상에 대한 설명)
이러한 머신러닝의 기법 중에 하나인 Supervised learning 기법은 우리의 실생활은 물론 현업에서도 많이 활용되고 있다.