
위에 첨부한 사진은 머신 러닝이라는 용어를 처음으로 사용하고 주변 사람들에게 전파한 아서 사무엘(Arthur Samuel) 교수님이시다. 우선 인공지능이라는 분야에 대해 공부를 시작했기 때문에 시초에 머신러닝이라는 용어를 가장 처음 사용한 사람에 대해서는 상식적으로 알고 있어야겠다고 생각했다.
자, 그럼 이번 포스팅에서는 입문자를 위한 인공지능/머신러닝 관련 강의를 듣고 개인적으로 학습한 내용을 정리해보겠다.
머신러닝(Machine Learning) ?
기계학습이란 명시적인 규칙없이 데이터 간 관련성을 스스로 찾아낼 수 있는 컴퓨터 프로그램을 말한다. 이는 1959년에 Arthur Samuel 교수가 한 말이다. 1998년에 Tom Mitchell은 특정 Task가 특정 경험을 통해 Perfermance measure를 얻었다면, 이러한 데이터의 반복 축적을 통해 컴퓨터가 더 나은방향으로 개선해나가게 되는데, 여기서 컴퓨터는 경험을 통해 자동으로 증진해나감에 집중한다.
E - DATA, T - CLASSIFICATION, P - ACCURRACY(정확도를 높이기 위해서는 데이터의 갯수를 늘린다)
전통적인 프로그래밍과 머신러닝의 접근법 차이
전통적인 프로그래밍에서는 프로그래머가 명시적으로 INPUT 값과 PROGRAM(RULES/ALGORISM)을 명시하고 결과 값으로 OUTPUT(ANSWER)을 도출해낸다. 반면 머신러닝은 INPUT 값과 OUTPUT값의 DATASET들을 명시하고 이를 통해 새로운 함수(RULES/ALGORISM)을 도출해낸다. 새롭게 도출해낸 함수를 통해 다른 값들이 들어왔을 때 결과값으로 어떤 값이 도출되는지 예측할 수 있다.
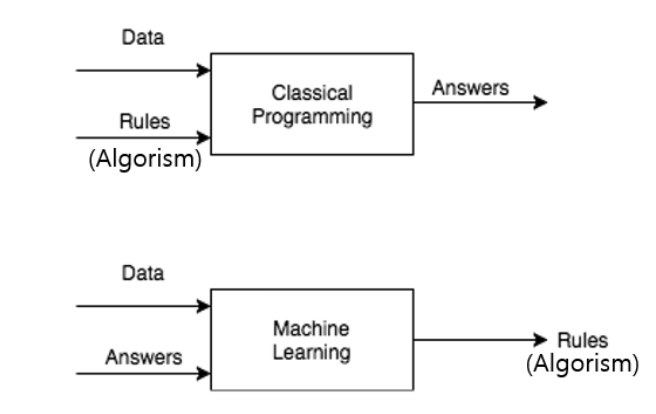
머신러닝의 예시
그렇다면 머신러닝의 예시로는 어떤 것들이 있을까?
(1) 강아지 사진이 주어졌을 때, 해당 영상이 어떤 레이블인지 분류
(2) 자연어 텍스트의 평점 예측ex) 너무 재미있어요 : 9.0/10.0
(3) vector값에 대한 영상 출력
위의 예시 모두 f:x → y 라는 관계가 성립된다. 여기서 x는 이미지, 자연어, vector가 될 수 있고, y는 레이블, continuous data, 영상이 될 수 있다.
머신러닝의 타입
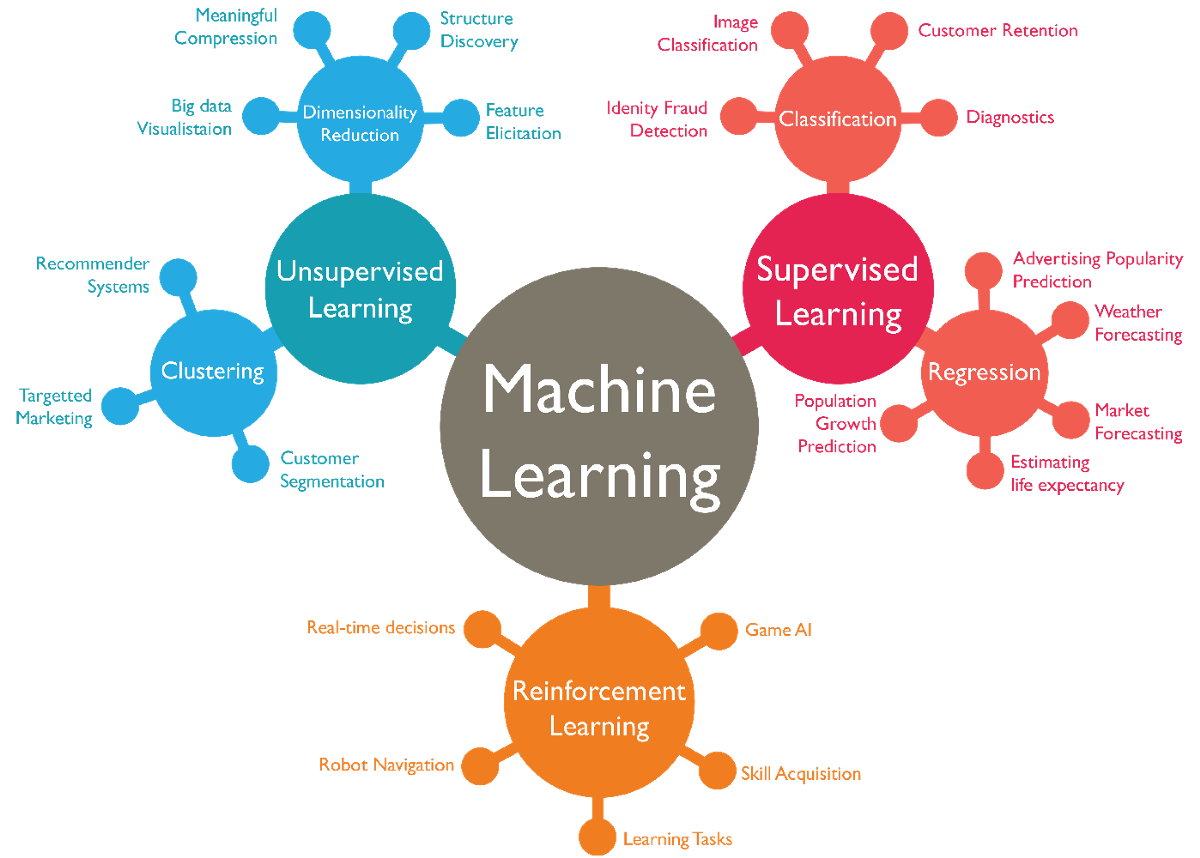
머신러닝의 타입에는 크게 두 분류로 나뉠 수 있다. feedback이 필요한 경우와 그렇지 않은 경우, teacher가 존재하는 경우와 그렇지 않은 경우로 나뉠 수 있다.
(1) Teacher가 존재하지 않는 경우는 Unsupervised Learning으로, feedback의 유/무와 관계없이 주어진 data(X)만으로 학습을 해서 결과 값(Y)를 추론하는 것이다.
구체적인 방법으로는, Dimensionality Reduction(차원 축소)가 있는데, 이는 입력된 고차원의 데이터를 의미있게 표현하는 방법에 대한 구현 방법이다. 또 다른 방법으로는 Clustering이 있는데, 이는 Supervised Learning의 Classification과 유사한 방법(단, y값이 주어지지 않는다)이다.
케이크 모형으로 살펴보면, Unsupervised Learning은 케이크의 거의 전체를 포함하는 비중으로, 전체 머신러닝에서 상당한 비중과 난이도를 포함한다.f(x)에서 값 x만으로 함수 f(x)의 결과 값 y를 도출해내야 하기 때문에 어렵다.
(2) Teacher가 존재하는 경우는 Supervised Learning과 Reinforcement Learning이 있다. Supervised Learing은 가장 많이 사용되는 형태의 머신 러닝으로, 직접적 피드백(Direct feedback)이 있다. (X,Y) PAIR 형태로 Labeling 작업된 데이터가 존재한다. 입력 데이터를 통해 결과 값을 추론하게 되므로 다른 방법에 비해 쉽게 해결될 수 있는 방법이다.y = f(x) 구체적인 방법으로는 Classification과 Regression(회귀)이 있으며, pair로 존재하는 (X,Y) 데이터에서 Y데이터의 성격에 따라 그 방법을 달리한다.
데이터 Y가 Categorical한 성격을 가지고 있다면, Classification, Continuous한 성격을 가지고 있다면 Regression(회귀)의 방법을 택한다.
케이크 모형으로 살펴보면, Supervised Learning은 케익의 데코레이션 부분인 icing 부분으로, 머신러닝에서 매우 적은 부분을 차지하고 있음을 알 수 있다.
(3) 마지막으로 Teacher가 존재하는 경우 중 간접적인 피드백(Indirect feedback)을 주는 경우인 Reinforcement Learning은 여러번의 action을 수행하여 간접적으로 어떤 action이 더 나은지 판단하는 방법이다.f(s,a) = r의 형태를 가지며, r(rewards)의 값이 최대화되는 a(action)을 도출해낸다. pair로 존재하는 (S,A) 데이터는 (입,출)을 담당하며, 강화학습의 주된 목적으로 사용된다.
Reward가 최대화 되는 방향으로 매 Step마다 Action을 선택해서 문제를 푸는 기법으로, Sequential data 환경에서 사용된다.
사용되는 분야로는 Game AI / Robot Navigation / Realtime decisions 등이 있다.
케이크 모형으로 살펴보면, Reinforcement Learning은 케이크의 데코로 올라간 체리와 같이 아주 작은 비중으로, 그 난이도는 가장 어렵다.y = f(x) that maximizes rPredict action y based on ob servation x to maximize a future reward r.
케이크를 통해 바라본 머신러닝의 타입
